
2024
4(80)
Bianka Kowalska*, Hubert Baran**, Daniil Hardzetski***,
Halina Kwaśnicka****, Aleksandra Marcinów*****,
Małgorzata Biegańska******
Analysis of the new architectural dataset NeoFaçade
and its potential in machine learning
DOI: 10.37190/arc240408
Published in open access. CC BY NC ND license
Abstract
The presence of articial intelligence (AI) in architecture has been growing rapidly in recent years. The collaboration between architects and
AI developers has led to signicant improvements in various design applications. Further development of machine learning techniques is highly
dependent on the availability of large, structured datasets. The aim of the article is to demonstrate the potential of a novel dataset, NeoFaçade, which
contains annotated pictures of historical tenements. A comparison of the dataset with existing benchmark datasets, the CMP Façade and the Paris Art-
Deco datasets, highlights its exceptional features. Its applications in three machine learning tasks are also presented: semantic segmentation, image
translation and image generation. In all three tasks, the models trained with NeoFaçade provide satisfactory results and indicate the great potential
of this collection. The planned further development of the dataset will allow the training of more precise models that will be able to distinguish more
elements and features of the façades and assist architects in designing tenements.
Key words: dataset, image processing, machine learning, architecture
Introduction
Architecture, as one of the oldest professions, has
evolved over centuries, and with it the tools of architec-
tural design. In recent years, articial intelligence (AI) has
emerged in the eld of architecture and has revolutionized
design optimization, empowering architects and designers.
Traditionally, architecture is associated with creativity,
aesthetics, and spatial design. However, in today’s world,
the scientic and technological aspects of design are also
playing an increasingly important role. This is where AI
comes in, oering new tools and opportunities for archi-
tects. For instance, AI was implemented in the design of
the Bo-DAA apartment project in Seoul, South Korea
(Rhee, Chung 2019).
Articial intelligence, especially Machine Learning (ML)
algorithms, neural networks, and vision systems, can be
used in various aspects of architecture. When applying AI
techniques, one should consider the ethical implications
of AI in architecture (Liang et al. 2024). The true power
of AI in architecture lies in its collaboration with human
architects (Bölek, Tutal, and Özbaşaran 2023). Combining
the knowledge of architects with AI techno logies opens the
way to innovative solutions and projects. It can improve
architecture’s eciency, functionality, and sustainability,
* ORCID: 0009-0008-6289-0762. Faculty of Information and
Communication Technology, Wrocław University of Science and Tech-
nology, Poland.
** ORCID: 0009-0001-2976-4923. Faculty of Information and
Communication Technology, Wrocław University of Science and Tech-
nology, Poland.
*** ORCID:0009-0001-2815-8948. Faculty of Information and
Communication Technology, Wrocław University of Science and Tech-
nology, Poland.
**** ORCID: 0000-0002-4368-4110. Faculty of Information and
Communication Technology, Wrocław University of Science and Tech-
nology, Poland, e-mail: halina.kwasnicka@pwr.edu.pl
***** ORCID: 0000-0003-4409-3563. Faculty of Architecture, Wro -
cław University of Science and Technology, Poland.
****** ORCID: 0009-0005-4302-2618. Faculty of Architecture, Wro-
cław University of Science and Technology, Poland.
76 Bianka Kowalska, Hubert Baran, Daniil Hardzetski, Halina Kwaśnicka, Aleksandra Marcinów, Małgorzata Biegańska
ensuring that architects feel valued and integral to the pro-
cess (Nabizadeh, Nabizadeh 2023).
Articial intelligence is a practical tool that can be used
in project management and construction, helping plan and
monitor work progress, optimize costs, and forecast pos-
sible problems. AI systems can analyze data related to the
operation of buildings, predict their energy consumption,
and respond to changes in environmental conditions in
real time, giving architects a sense of condence and reas-
surance in their work. Using AI techniques, designers can
generate and analyze thousands of design concepts, identi-
fy optimal solutions, or respond quickly to changing needs
and requirements (Sourek 2024).
The presence of articial intelligence in architecture has
been increasing since 2012 and remains a topic of growing
interest. Publications cover various applications, from per-
formance-based studies to spatial programming and resto-
ration work (Bölek, Tutal, and Özbaşaran 2023). In recent
years, generative articial intelligence has made a notable
surge within the realm of architecture, benetting from the
rapid growth of deep models, such as generative adversar-
ial networks (GANs) (Li et al. 2024). GANs consist of two
networks: a generator, trained to produce outputs that can-
not be distinguished from real images, and a discriminator,
which is trained to detect the generator’s fakes. Advanced
generative models are capable of generating multiple de-
sign options in a short time, allowing architects to explore
dierent design concepts quickly. AI takes over repetitive
tasks, allowing architects to focus on the design’s creative
and strategic aspects.
One of the challenging design tasks is designing histor-
ical tenement façades, since the façade must be placed in
the tight proximity of other buildings as well as meet the
historical and cultural demands of the region. AI has also
been employed in this context, with applications including
the analysis of historical building data and the generation
of design recommendations based on popular architectur-
al styles from a specic era (Enjellina, Beyan and Rossy
2023).
This paper demonstrates the potential of the authors’
dataset, NeoFaçade, using some example applications.
The usefulness of this dataset is compared to two acces-
sible benchmark datasets, but from dierent cities and ar-
chitectural styles. NeoFaçade was created by a team from
Wrocław University of Science and Technology. It con-
tains façades of Wrocław’s buildings, mainly from the 19
th
century. The intention is to use this dataset and others to
renovate existing tenement façades or to construct inlls
between old buildings. In the next stage, this dataset will
be expanded with photos of tenement façades from Ber-
lin and Szczecin, since the tenements in these cities are of
a similar style. More information about the current version
of NeoFaçade can be found in (Marcinów et al. 2024). It is
worth mentioning that we plan to make this dataset avail-
able for research.
The paper is structured as follows: Section 2 briey
reviews the related work on the topic. The third section
describes the datasets used in experiments, and the fourth
section presents the results of various experiments. The
summary concludes the paper.
Related work
In recent years, there has been a notable rise in the quan-
tity of studies on architectural design that makes use of
generative AI. Our perception of visual culture becomes
more mechanic with time, which inuences architecture.
This problem is considered in (Yau et al. 2023), where the
authors debunk the three ways of thinking about architec-
tural form in order to “lay the foundational preconditions
for a machine-learnable architecture.” Most of the work
focuses on architectural plan design, which includes cre-
ating horizontal section views at specic site elevations
guided by objective conditions and subjective decisions.
Many authors point out that more research is needed in
the
elds of structural system design, architectural 3D form
re-
nement and optimization design, and architectural façade
design (Sourek 2024; Ploennigs, Berger 2023; Nabiza-
deh, Nabizadeh 2023; Li et al. 2024; Bölek, Tutal, and
Özbaşaran 2023).
The applications of generative AI in structural system
design primarily involve the prediction of structural lay-
out and structural dimensions (Pizarro et al. 2021). In the
Bo-DAA apartment project described above, the architects
utilized a 3D model and architectural plan to dene the
building’s spatial form and structural load distribution
(Rhee, Chung 2019).
Façade design aims to create the building’s external ap-
pearance and includes all structural design demands and
encapsulates the areas and positions of façade elements
while adopting a specic style. Applications of generative
AI in architectural façade design encompass two primary
categories: the generation of façade images, typically em-
ploying semantic segmentation maps of the façades, and
the generation of semantic segmentation maps based on
2D images (Xie et al. 2021). Segmentation is a popular
problem in computer vision. In semantic segmentation, we
want to train a model that will assign a label to each pix-
el for a given image; this is in contrast to classication,
where we assign only one label to a whole image (Peng
et al. 2020). The generation approach utilizing semantic
segmentation consequently involves generating images
under the geometrical constraints of the given area. It can
be posed as translating an input image into a corresponding
output image. In 2018, Pix2Pix was introduced; this im-
age-to-image translation method is capable of translating
one possible representation of a scene into another using
deep learning, given sucient training data (Isola et al.
2017). The framework employs GANs in a conditional
setting, meaning that the generator is tasked with not only
fooling the discriminator, but also being near the ground
truth output (Newton 2019; Gui et al. 2021). The authors
explored the generality of conditional GANs by testing the
method on various tasks, for example, map to aerial photo,
day to night, black-and-white to color, and architectural la-
bels to façade photo.
Following the successful deployment of the Transform-
ers architecture in natural language processing tasks, there
has been a growing interest in adapting Transformers for
computer vision. The rst model was a vision Transformer
(ViT) created for classication tasks. ViT architecture was

Analysis of the new architectural dataset NeoFaçade and its potential in machine learning 77
later used in segmentation transformer (SETR) architec-
ture to study the performance of Transformers in semantic
segmentation tasks. SETR achieved promising results, and
further work began to create a better architecture utilizing
Transformers without SETR’s limitations. One of those
architectures is SegFormer (Xie et al. 2021). Its main dif-
ference is that it utilizes Mix Transformers (MiT), which
return multi-scale features, while ViT returns only single-
scale features. SegFormer shows good accuracy and run
time on benchmark datasets.
Although models based on neural networks are undeni-
ably the most popular articial intelligence models these
days, other approaches also have applications in various
architecture-related tasks. In the eld of façade image
generation, stochastic split grammars are used to build fa-
çade structure-aware generative models (Riemenschneider
et al. 2012; Martinovic, Van Gool 2013a; Gadde, Marlet
and Paragios 2016). A split grammar generates a façade
image by splitting a given input shape into a set of smaller
shapes, where each shape represents some part of a façade
image. For instance, if the input shape is a rectangle repre-
senting a building, the split grammar might divide it into
smaller rectangles representing the stories of the building.
This process continues until the desired level of detail is-
reached and the nal shapes are obtained (e.g., doors or
windows), which are called terminals. In such a grammar,
one may “merge” two shapes to be used interchangeably
(with some probabilities) and obtain a stochastic gram-
mar that can generate new façade examples. The ap-
proach may be extended to generating semantic segmenta-
tion masks.
Data used in experiments
Machine learning models require large amounts of high-
quality training data to learn complex patterns and re la-
tionships within them eectively. The scarcity of struc tured
architectural training data presents a signicant challenge,
undermining the initial stages of model training. There-
fore, the NeoFaçade dataset obtained by ( Marcinów et al.
2024) is a crucial asset for developing com prehensive, pre-
cise models.
NeoFaçade represents a novel approach to addressing
the growing demand for structured, high-quality data in the
eld of architecture. The dataset contains 400 annotated
images of tenement façades in Wrocław. The images rep-
resent a variety of architectural styles from the 19
th
and
20
th
centuries. Each image is assigned a color-coded anno-
tation mask, where the colors represent the various façade
elements (e.g., windows, cornices, or details). A detailed
description of the dataset and its creation is available in
(Marcinów et al. 2024).
As the ecacy of AI models is highly dependent on
the quality of the data used for training, it is essential to
conduct a comparative analysis to compare NeoFaçade
with existing benchmark datasets. Two available datasets
of similar content and structure are the Center for Ma-
chine Perception (CMP) Façade Dataset (Tyleček, Šára
2013) and the Paris ArtDeco Dataset (Gadde, Marlet, and
Paragios 2016). These datasets were selected because of
their shared theme and labels, with the images depicting
residential buildings and sharing elements of interest, such
as balconies or details. The former consists of 378 recti-
ed and cropped façade images from various locations.
The pictures were manually annotated by the authors with
a set of overlapping rectangular shapes, each coded to
represent one of the 12 classes that were distinguished in
the collection. The latter contains 79 façade images from
Paris following the Art Deco style. Each picture is asso-
ciated with an annotation text le containing a matrix of
numbers in the image shape. Each number represents one
of the seven classes featured in the collection. Figure 1 il-
lustrates example pictures and their annotations from both
datasets.
Compared to the other two datasets, NeoFaçade is dis-
tinguished by its larger set of images and their higher res-
olution, as shown in Table 1. The number of basic façade
elements distinguished in the set is the same as in the CMP
dataset, while Paris ArtDeco is characterized by the lowest
number of classes.
Fig. 1. Example pictures and their annotations from the CMP dataset (left) and Paris ArtDeco (right)
(elaborated by B. Kowalska)
Il. 1. Przykładowe zdjęcia i ich adnotacje ze zbioru danych CMP (po lewej) i Paris ArtDeco (po prawej)
(oprac. B. Kowalska)
78 Bianka Kowalska, Hubert Baran, Daniil Hardzetski, Halina Kwaśnicka, Aleksandra Marcinów, Małgorzata Biegańska
The Paris ArtDeco dataset exhibits the most balanced
distribution of classes, with all distinguished elements oc-
curring in almost all images. This is due to its elements be-
ing more common and the dataset not focusing on specic
architectural details. In contrast, the other datasets display
less of a balance among classes. The CMP dataset and
NeoFaçade exhibit a comparable imbalance ratio (the ratio
of majority class to minority class).
The exceptionally high resolution of images within Neo-
Façade allows us to generate images of exceptional qual-
ity and to conduct a detailed analysis of tenement façades
from the 19
th
and 20
th
centuries. The dataset comparison
provides a comprehensive analysis of multiple datasets
within the eld of architecture, revealing dierences in
terms of size, scope, and quality. The analysis conrms the
value and potential impact of NeoFaçade for driving fu-
ture research advancements. The usefulness of the dataset
was briey studied; the experiments are presented in the
next section.
Verification of the dataset’s potential
in machine learning tasks
In the case of façade generation, the main tasks are seg-
mentation and image translation. In this section, we present
the results of three ML models used for these tasks, which
were trained and evaluated using the data described above.
Semantic segmentation
One of the popular tasks in computer vision systems is
semantic segmentation. This process assigns a label to ev-
ery pixel, providing a detailed understanding of the image’s
contents. Several techniques have been developed for this
task; they involve classifying each pixel in an image into
a predened category. Semantic segmentation is a power-
ful technique for detailed image analysis, enabling precise
understanding and categorization of every part of an image.
We trained the SegFormer model using a pre-existing
implementation (Yin et al. 2023) with the three datasets
described in Section 3 in order to evaluate how well-suited
the datasets are for semantic segmentation. The objective
of this experiment was to:
– compare the performance of the model trained on
NeoFaçade against those trained on existing benchmark
datasets,
– identify the common problems encountered in façade
semantic segmentation, and
– identify the specic issues associated with training the
model on NeoFaçade.
Figures 2 and 3 illustrate the segmentation results of
models trained and evaluated with the three aforemen-
tioned
d
atasets. Upon initial observation, the model de mon -
strates an ability to identify the majority of classes. The an-
notations
produced by the model are placed correctly but
do not maintain the original rectangular shapes.
Table 2 presents the metrics of the SegFormer trained
on the three datasets. Notably, the results of the model
trained on NeoFaçade fall between the other two models.
This can be attributed to the characteristics of the data. The
Paris ArtDeco dataset, for instance, features fewer classes
and clear façade images. In contrast, the CMP dataset of-
ten includes foreign objects in the pictures, such as trees
that heavily cover the façades. We can use some metrics to
evaluate the performance of the trained model. The popu-
lar ones are as follows:
– Precision – the ratio of correctly predicted positive
observations to the total predicted positive observations.
– Recall – the ratio of correctly predicted positive ob-
servations to all observations in a given class.
– F1 measure – a harmonic mean of recall and precision
which evenly takes into account precision and recall and is
more suitable for comparing models.
Four measures obtained on three datasets are shown
in Table 2. MacroAvg (macro-average F1 measure) is an
F1 measure that is calculated separately for each class,
then averaged using the arithmetic mean. It is unsuitable
for imbalanced data because it prefers dominant classes.
Weighted Avg F1 (weighted average F1 measure) is an F1
measure calculated for each class separately and averaged
with weights depending on the number of true labels of
each class. The weight of class x depends on the propor-
tion of data belonging to that class within the dataset.
This measure considers the minor classes and is better
for imbalanced data. The situation is similar with preci-
sion measurement: Macro Avg Precision and Weighted Avg
Precision.
The number of classes in NeoFaçade is comparable
to that of the CMP dataset. However, unlike in CMP, the
data is less obscured by foreign objects. Consequently, the
weighted average of metrics is very similar for the Neo-
Façade and Paris ArtDeco datasets.
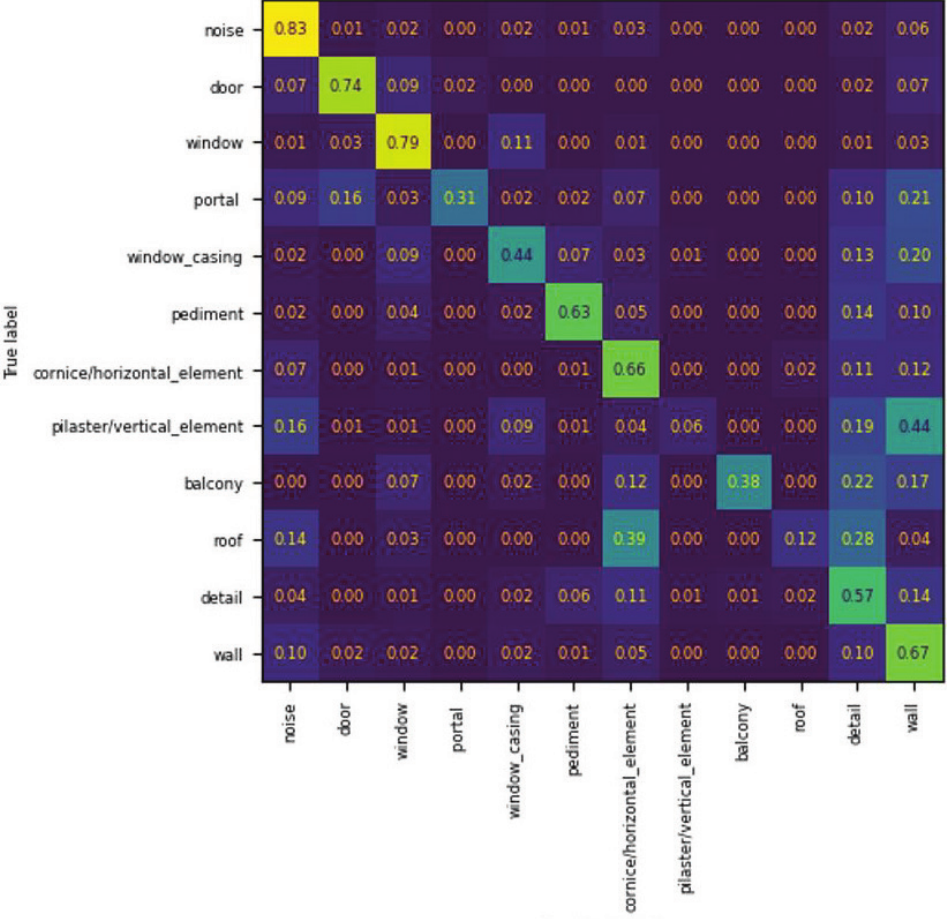
To gain further insight into the model’s performance,
it is necessary to analyze the confusion matrix (Fig. 4).
A confusion matrix is a matrix that provides an overview
of the performance of a machine learning model on a set of
test data. It is a tool for visualizing and analyzing the accu-
racy of a model’s predictions and is frequently employed
to assess the eectiveness of models designed to assign
a categorical label to each data input. The matrix compares
predicted labels to true labels, which indicates the exact
mistakes the model made. Instances where the prediction
was accurate are represented on the diagonal of the matrix.
Dataset NeoFaçade CMP
Paris
ArtDeco
Number of
pictures
400 378 79
Number
of classes
12 12 7
City Wrocław various Paris
Mean resolution
[MPx]
11.71 0.65 0.26
Imbalance ratio 2.62 2.61 1.11
Table 1. Comparison of façade datasets (elaborated by B. Kowalska)
Tabela 1. Porównanie zawartości zbiorów danych (oprac. B. Kowalska)

Analysis of the new architectural dataset NeoFaçade and its potential in machine learning 79
Fig. 2. Ground truth annotations and semantic segmentation results on the CMP dataset (left) and Paris ArtDeco (right)
(elaborated by D. Hardzetski)
Il. 2. Oryginalna anotacja i wyniki segmentacji semantycznej na zbiorze CMP (po lewej) i zbiorze Paris ArtDeco (po prawej)
(oprac. D. Hardzetski)
Fig. 3. Ground truth annotation and semantic segmentation results on the NeoFaçade dataset (elaborated by D. Hardzetski)
Il. 3. Oryginalna anotacja i wyniki segmentacji semantycznej na zbiorze NeoFaçade (oprac. D. Hardzetski)
Table 2. SegFormer – performance measures for three datasets (elaborated by D. Hardzetski)
Tabela 2. SegFormer – miary skuteczności dla trzech zbiorów danych (oprac. D. Hardzetski)
Model Macro Avg F1 Weighted Avg F1 Macro Avg Precision Weighted Avg Precision
CMP 0.42 0.60 0.51 0.62
Paris ArtDeco 0.61 0.75 0.68 0.76
NeoFaçade 0.50 0.73 0.54 0.75
80 Bianka Kowalska, Hubert Baran, Daniil Hardzetski, Halina Kwaśnicka, Aleksandra Marcinów, Małgorzata Biegańska
The most prevalent error in the model trained on Neo-
Façade was various classes being mislabeled as a wall, al-
though this issue was also present in the two other models.
This is attributed to the fact that the real labels are not pre-
cise at pixel level and the model has an error in determin-
ing the shape of an object. The model does not correctly
determine the contour of an element, but it still nds it in
the correct spot.
A further limitation of the model is its tendency to mis-
label other classes as the detail class. This occurs when the
model mistakenly identies other wall elements, such as
window frames and cornices, as details due to their visual
similarities. Balconies and roofs may be the most surpris-
ing of these mislabeled classes. This can be attributed to the
model’s inability to accurately comprehend these objects’
volume. In images, these elements appear at and have a dif-
ferent texture than the wall, which may lead to mislabeling.
The most challenging objects for our model are ver-
tical elements. The model exhibited a complete inability
to identify this label. Based on the examples containing
this class, we may assume the reason for such poor per-
formance is that the elements in question closely resemble
walls. The main distinct feature of vertical elements is their
pillar shape, which our model failed to learn.
Image translation
Image-to-image translation is the process-s of trans-
forming an input image into an output image while pre-
serving some semantic properties. It encompasses a range
of tasks, including image synthesis, resolution enhance-
ment or image colorization. In the case of the NeoFaçade
dataset, image translation can be utilized to transform se-
mantic segmentation masks into real façade images.
Fig. 4. Confusion matrix – performance of the model on NeoFaçade (elaborated by D. Hardzetski)
Il. 4. Macierz pomyłek – działanie modelu na zbiorze NeoFaçade (oprac. D. Hardzetski)

Analysis of the new architectural dataset NeoFaçade and its potential in machine learning 81
In the experiment, the ready-made implementation of
the Pix2Pix model was used (Isola et al. 2017). The model
consists of two neural networks: a generator, whose task is
to generate new images, and a discriminator, which classi-
es whether the generated image is real or fake. The gen-
erator learns the underlying connections between images
from the two domains (segmentation masks and façade
images) and the discriminator examines each fragment of
the generated picture and attempts to classify the patch as
authentic or articial. The discriminator’s examination of
individual small parts of the image facilitates sharp and
detailed results with the Pix2Pix model.
The model was trained for 250 epochs on two datasets
separately: NeoFaçade and CMP. Figures 5 and 6 illu strate
the example results of the Pix2Pix model on the translation
task (segmentation mask to façade image).
In both cases, the model was able to correctly generate
desired façade elements in the relevant locations. However,
more detailed objects, such as transoms and balconies, ap-
pear blurred in the generated images. This is because they
occur less frequently in the datasets. The model encounters
diculties lling in the blank gaps left in the images due
to image warping.
Façade generation with grammars
We applied generative grammar for façade generation, in-
spired by the approach from (Martinovic, Van Gool 2013a).
Several models were trained on small subsets of the data-
set. First, a rectangular lattice was generated for each
façade example, using pixel labels from the segmentation
mask. Lattices were built similarly to the one proposed
by (Riemenschneider et al. 2012), with the additional re-
moval of redundant split lines. Next, each façade lattice
was converted into a hierarchical structure called a parse
tree, which broke down a façade into oors and then into
smaller parts.
Then, parse trees were converted into grammars and
merged into one grammar, containing shapes from all fa -
çades in the training set. The merged grammar underwent
symbol merging. The best symbols to merge were chosen
by parsing candidate grammars from merging with 2D
Segmentation mask Original image Predicted image
Segmentation mask Original image Predicted image
Fig. 5. Results of the image2image translation task on NeoFaçade images (elaborated by B. Kowalska)
Il. 5. Wynik zadania translacji image2image na obrazach ze zbioru NeoFaçade (oprac. B. Kowalska)
Fig. 6. Results of the image2image translation task on CMP dataset (elaborated by B. Kowalska)
Il. 6. Wynik zadania translacji image2image na obrazach ze zbioru CMP (oprac. B. Kowalska)

82 Bianka Kowalska, Hubert Baran, Daniil Hardzetski, Halina Kwaśnicka, Aleksandra Marcinów, Małgorzata Biegańska
Earley Parser (Martinovic, Van Gool 2013b) and calculat-
ing their log-likelihood.
In Figure 7, the left column presents examples of gen-
erated façade images. The right column shows examples
from the training set that are the most similar to the gener-
ated ones. The model basically generates input examples
with some small modications (e.g., a window is replaced
with another window, possibly from another input façade
image). More training steps could make induced grammars
introduce more modications to the input images.
Summary
The primary aim of this study was to present and ana-
lyze the innovative architectural dataset NeoFaçade, high-
lighting its potential applications in machine learning. We
demonstrated its quality and versatility by comparing this
collection with two benchmark datasets of similar structure.
Our analysis included the evaluation of three dierent
machine learning models: semantic segmentation, image
translation, and image generation. Each model was tested
using the dataset and the results underscored the dataset’s
ability to produce satisfactory outcomes across these var-
ied tasks. These ndings suggest signicant potential for
further renement and optimization in future studies.
The continuous expansion of the dataset, incorporating
additional photographic material from diverse urban loca-
tions, is anticipated to enhance its applicability and per-
formance. This ongoing enrichment is expected to yield
increasingly favorable results, paving the way for devel-
Fig. 7. Façade generation
with grammars using NeoFaçade:
generated façades on the left
and similar real photos
in the data set on the right
(elaborated by H. Baran)
Il. 7. Generowanie fasad
z zastosowaniem gramatyki
dla zbioru NeoFaçade:
po lewej wygenerowane fasady,
po prawej – najbardziej podobne
zdjęcia ze zbioru danych
(oprac. H. Baran)
Analysis of the new architectural dataset NeoFaçade and its potential in machine learning 83
oping an architect-friendly generative model capable of
producing highly detailed and contextually accurate archi-
tectural designs.
Future research will focus on leveraging the detailed
metadata included in the dataset. This metadata encom-
passes basic elements of façades and distinguishes between
various architectural styles and elements. Such compre-
hensive annotations oer a rich source of information that
can be employed to train more precise and more sophisti-
cated models. These models will be capable of generating
façades that adhere to rigorous architectural and spatial
specications, thereby meeting the high standards required
in professional architectural design.
Moreover, the planned inclusion of tenements from
Berlin and Szczecin will further enhance the dataset’s di-
versity and robustness. This expansion is expected to sig-
nicantly improve the performance of the presented mod-
els, leading to better and more accurate results. The dataset
will provide a more comprehensive foundation for training
advanced machine learning models by incorporating these
additional urban landscapes.
The NeoFaçade dataset stands out as a high-quality re-
source for machine learning applications in architecture.
Its rich and detailed annotations, combined with contin-
uous updates and expansions, position it as a valuable
tool for developing innovative solutions in architectural
design. The ndings of this study highlight the dataset’s
potential to support the creation of advanced, generative
models that align with the precise demands of architec-
tural practice.
References
Bölek, Buse, Osman Tutal, and Hakan Özbaşaran. “A systematic review
on articial intelligence applications in architecture.” Journal of
Design for Resilience in Architecture and Planning 4, no 1 (2023):
91–104. https://doi.org/10.47818/DRArch.2023.v4i1085.
Enjellina, Eleonora Vilgia Putri Beyan, and Anastasya Gisela Cinintya
Rossy. “Review of AI Image Generator: Inuences, challenges, and
future prospects for architectural eld.” Journal of Articial Intelli-
gence in Architecture (JARINA) 2, no. 1 (2023): 53–65. https://doi.
org/10.24002/jarina.v2i1.6662.
Gadde, Raghudeep, Renaud Marlet, and Nikos Paragios. “Learning gram -
mars
for architecture-specic facade parsing.” International Jour-
nal of Computer Vision 117, no. 3 (2016): 290–316. https://doi.
org/10.1007/s11263-016-0887-4.
Gui, Yingbin, Biao Zhou, Xiongyao Xie, Wensheng Li, and Xifang Zhou.
“GAN-Based Method for generative design of visual comfort in un-
derground space.” IOP Conference Series: Earth and Environmen-
tal Science 861, no. 7 (2021): 072015. https://doi.org/10.1088/1755-
1315/861/7/072015.
Isola, Phillip, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. “Image-
to-Image Translation with conditional adversarial networks.” 2017
IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
(2017): 5967–76. https://doi.org/10.1109/CVPR.2017.632.
Li, Chengyuan, Tianyu Zhang, Xusheng Du, Ye Zhang, and Haoran Xie.
“Generative AI models for dierent steps in architectural design:
A literature review.” Frontiers of Architectural Research (2024).
https://doi.org/10.1016/j.foar.2024.10.001.
Liang, Ci-Jyun, Thai-Hoa Le, Youngjib Ham, Bharadwaj R.K. Mantha,
Marvin H. Cheng, and Jacob J. Lin. “Ethics of articial intelligence
and robotics in the architecture, engineering, and construction in-
dustry.” Automation in Construction 162 (June 2024): 105369.
https://doi.org/10.1016/j.autcon.2024.105369.
Marcinów, Aleksandra, Małgorzata Biegańska, Bianka Kowalska, Hu-
bert Baran, Daniil Hardzetski, and Halina Kwaśnicka. “Building
a dataset of Wrocław’s historic tenements: Image annotation for ma-
chine learning applications.” Architectus 79, no. 3 (2024): 55–64.
https://doi.org/10.37190/arc240306.
Martinovic, Andelo, and Luc Van Gool. “Bayesian grammar learning
for inverse procedural modeling.” 2013 IEEE Conference on Com-
puter Vision and Pattern Recognition (2013a): 201–8. https://doi.
org/10.1109/CVPR.2013.33.
Martinovic, Andelo, and Luc Van Gool. “Early Parsing for 2D Stochastic
Context Free Grammars.” Technical Report KUL/ESAT/PSI/1301,
KU Leuven, 2013b.
Nabizadeh Rafsanjani, Hamed, and Amir Hossein Nabizadeh. “Towards
human-centered articial intelligence (AI) in architecture, engineer-
ing, and construction (AEC) industry.” Computers in Human Be-
havior Reports 11 (August 2023): 100319. https://doi.org/10.1016/j.
chbr.2023.100319.
Newton, David. “Generative deep learning in architectural design.”
Tech nology|Architecture + Design 3, no. 2 (2019): 176–89. https://
doi.org/10.1080/24751448.2019.1640536.
Pizarro, Pablo N., Leonardo M. Massone, Fabián R. Rojas, and Rafael
O. Ruiz. “Use of convolutional networks in the conceptual structural
design of shear wall buildings layout.” Engineering Structures 239
(2021): 112311. https://doi.org/10.1016/j.engstruct.2021.112311.
Peng, Jizong, Guillermo Estrada, Marco Pedersoli, and Christian Des-
rosiers. “Deep co-training for semi-supervised image segmenta-
tion.” Pattern Recognition 107 (November 2020): 107269. https://
doi.org/10.1016/j.patcog.2020.107269.
Ploennigs, Joern, and Markus Berger. “AI art in architecture.” AI in
Civil Engineering 2, 8 (2023). https://doi.org/10.1007/s43503-023-
00018-y.
Rhee, Jinmo, and Jae-Won Chung. “Applicability of Articial Intelligence
in Apartment Complex Design.” In Annual Conference in Architec-
tural Institute of Korea, 2019.
Riemenschneider, Hayko, Urlich Krispel, Wolfgang Thaller, Michael Do-
noser, Sven Havemann, Dieter Fellner, and Horst Bischof. “Irre gu-
lar lattices for complex shape grammar facade parsing.” 2012 IEEE
Conference on Computer Vision and Pattern Recognition (2012):
1640–47. https://doi.org/10.1109/CVPR.2012.6247857.
Sourek, Michal. “AI in architecture and engineering from misconcep tions
to game-changing prospects.” Architectural Intelligence 3, 4 (2024).
https://doi.org/10.1007/s44223-023-00046-9.
Tyleček, Radim, and Radim Šára. “Spatial pattern templates for recog-
nition of objects with regular structure.” In Pattern Recognition.
GCPR 2013. Lecture Notes in Computer Science, edited by Joachim
Acknowledgements
This research was funded by the NCN Miniatura 7 Grant, number 2023/
07/X/ST8/01424.
We would like to express our gratitude to all those who have contribu-
ted to this project: scholars from the chair of the History of Architecture,
Art and Technology of the Faculty of Architecture of Wrocław University
of Science and Technology (Aleksandra Brzozowska-Jawornicka, PhD
Arch, Bartłomiej Ćmielewski, PhD, Maria Legut-Pintal, PhD and Ro-
land Mruczek, PhD) and the students of the Faculty of Architecture, who
took the photographs of the tenements and carried out the annotation
(with particular thanks to Katarzyna Blicharz and Agnieszka Pałka).
84 Bianka Kowalska, Hubert Baran, Daniil Hardzetski, Halina Kwaśnicka, Aleksandra Marcinów, Małgorzata Biegańska
Streszczenie
Analiza nowego zbioru danych architektonicznych NeoFaçade oraz jego potencjału w uczeniu maszynowym
Rola sztucznej inteligencji (AI) w architekturze gwałtownie wzrosła w ciągu ostatnich lat. Współpraca między architektami i programistami
AI doprowadziła do usprawnień w wielu dziedzinach projektowych. Dalszy rozwój technik maszynowego uczenia w znacznym stopniu zależy od
dostępności dużych i ustrukturyzowanych zbiorów danych. Celem autorów artykułu jest pokazanie potencjału nowego zbioru danych, nazwanego
NeoFaçade, zawierającego opisane (anotowane) obrazy kamienic historycznych. Porównując zbiór z innymi ogólnodostępnymi zbiorami – CMP
Facade oraz Paris ArtDeco – podkreślono jego potencjalną użyteczność. Zaprezentowane również zostało wykorzystanie zbioru w trzech zadaniach
uczenia maszynowego: segmentacji semantycznej, translacji obrazów z generacji obrazów. We wszystkich trzech zadaniach modele wytrenowane na
zbiorze NeoFaçade dają satysfakcjonujące wyniki i wskazują na wysoki potencjał zbioru. Planowany dalszy rozwój zbioru umożliwi wytrenowanie
dokładniejszych modeli, które będą w stanie rozróżniać więcej elementów i cech fasad oraz wspomagać architektów w projektowaniu kamienic.
Słowa kluczowe: zbiór danych, przetwarzanie obrazów, uczenie maszynowe, architektura
Weickert, Matthias Hein, Bernt Schiele, Springer, 2013. https://doi.
org/10.1007/978-3-642-40602-7_39.
Xie, Enze, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Al-
varez, and Ping Luo. “SegFormer: Simple and ecient design for
semantic segmentation with transformers.” (2021). https://doi.org/
10.48550/arXiv.2105.15203.
Yau, Ho Man, Theodoros Dounas, Wassim Jabi, and Davide Lombardi.
“Timber joints analysis and design using shape and graph grammar-
based machine learning approach.” In
Digital Design Reconsidered
– Pro ceedings of the 41
st
Conference on Education and Research in
Com puter Aided Architectural Design in Europe (eCAADe 2023),
20–23 September 2023, Graz, Austria, edited by Wolfgang Dokonal,
Urs Hirschberg, Gabriel Wurzer. Vol. 1. eCAADe, 2023. https://doi.
org/ 10.52842/conf.ecaade.2023.1.569.
Yin, Wei, Yifan Liu, Chunhua Shen, and Baichuan Sun. “SSIW.” Ac-
cessed 2023. https://github.com/Xpitre/SSIW/.